![]()
|
|
|
|
Introduction |
Important syntax things of the language are: |
||
|
One class - one module
|
||
|
Double naming of types, variables, functions, constants
|
||
|
Names of classes, enumerations and records are always written in figure brackets
|
||
|
Source code string length restriction
|
||
|
A rule to continue line of code
|
||
|
Static function with a single parameter can be called always in a postfix form
|
||
|
Arrays are always used together with its square brackets:
|
||
|
A line of code contains only a single statement
|
||
|
Restrictions on a code quality:
|
|
Overloading operators
|
The language has lack of: |
||
|
Preprocessor
|
||
|
Function pointers
|
||
|
Array as a result of a function
|
||
|
Multiple inheritance
|
||
|
go to statement
|
||
|
Character data type
|
||
|
Precision specification for simple data type variables
|
||
|
Implicit type conversions for distinct data types
|
||
|
Handling exceptions
|
I. Syntax |
I. 1. Formatting statements |
I. 1. a. Continue statement lines |
|
Statements need not any finalization symbol (like ' Symbol ';' is used to finish a block of statements. E.g.:
|
|
A line of a code should not exceed 80 characters (without ending comments and spaces and tabulations). Statement can be continued in several lines only in following cases:
|
|
Another way to remember the rule is that a statement is continued only if:
|
|
Or use the following figure:
|
|
To simplify understanding code containing long lines of code with continuations onto another lines, it is recommended to separate all such lines from other lines in blocks with empty lines. (The compiler warns about such possibility). |
I. 1. b. Block statements |
|
Block statements always are starting in a new line. Nesting statements block is ended with the symbol ';'. Functions and other blocks of a class level are ending with a symbol '.'. Such blocks are: a class header, an import list, enumeration declaration, constants definition block. (Though it is allowed to use ';' for an import list, too). The last line in a nested block can not be ended with block closing brackets. But it is allowed to place the '.' symbol ending a function following the last block closing bracket anyway. E.g.:
|
FOR i IN [1
TO 100] :
|
|
There is only a single keyword for a conditional statement ( All other statements are simple: |
|
A compiler requires to mark with a modifier
|
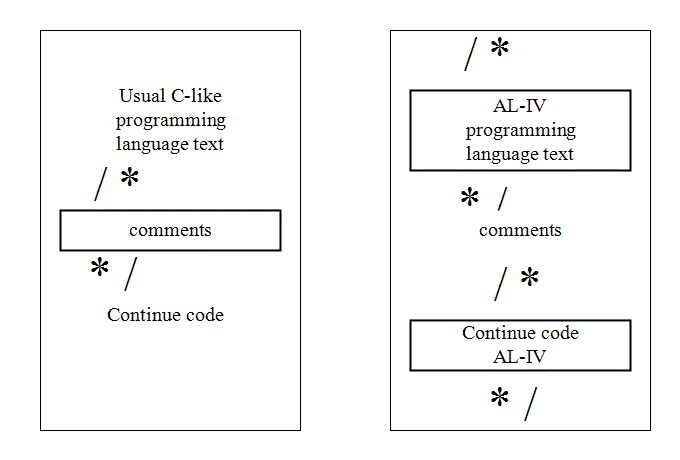
I. 1. c. Comments |
See the figure:
|
|
I. 1. d. Case sensitivity for keywords, types and other identifiers |
|
Type names create a name space not intersecting other names at all. |
It is desired to be written CAPITALIZED.
|
|
So, A and a are different variables (or constants). Names of Public fields, functions, variables, types are always starting from a capital letter. All other names are local in a module. (This does not concern local variables which are always local in its functions and can be written from any case).
|
I. 1. e. Naming |
|
While declaring a variable, a function, a data type, a table or an enumeration item it's long name can be separated by the symbol '|' onto parts, the first of which is a short name. Also, the symbol '||' can be used to define another name chain, and so on. It is therefore required that all such chains should start from the same letter (though letter case can be different).
There are following rules:
|
|
Functions names, variables, fields names (of classes and structures), table names and names of enumeration items are identifiers starting from a letter. Names of {Classes} are identifiers enclosed by figure brackets and starting from a capital letter. Names of {structures} and {enumerations} also are identifiers in figure brackets but starting from a lowercase letter. Enumeration 'ITEMS' are written in apostrophes. Still these are constants it is recommended to use CAPITALIZED names. |
I. 1. f. Modifiers |
|
Many language declarations (module header, statement, variable of data type declaration) can have modifiers.
|
|
Modifiers do not affect main code semantics. These just help to compiler to provide more security and sometimes help to optimize resulting code. If to remove all modifiers in a ready program (and suppose that a language do not require it), this
(usually) do not change a result of the program (but can take an effect of changing its size / working
speed, either increasing or decreasing it).
In some cases a presence of some identifier in the name of a variable itself is used as a "modifier". E.g., the word "dummy" as a part of a name can be used to prevent the compiler to warn about a variable which is not used in code. And the word temp in a local variable name determines for the compiler that the variable is a temporary and it is not necessary to warn the programmer about assigning a new object to that variable only. |
I. 2. Assignment |
I. 2. a. Simple assignment statement |
where |
|
|
To compare for equality of two operands a "C"-like operator |
I. 2. b. Assignment in combination with arithmetic, logic or bitwise operation |
|
Additional operations |
|
It is possible to use the symbol '_' at the right side of the sign '=' in place of the value left to the assignment sign '=' instead of using such extend assignments. |
I. 2. c. Data sending operations |
|
Operation
|
|
A similar operation
Additionally, right to the >> operator a declaration of a new variable can be specified.
|
I. 2. d. Repeating assignment and sending data operators |
|
If a statement is starting from a symbol For such repeating assignment statement (or data sending statement):
|
I. 3. Expressions |
| Actually an expression in the AL-IV is either a constant or a variable or a unction call, which (sometimes) is receiving parameters which are expressions again. And there are some special functions accepting one or two parameters and returning a result which are described as "embedded" binary or unary operations. Below is the table of such embedded operations with its priorities. |
|
I. 3. a. Checking the presence of an item |
|
Operators
In case of a constructed array, all its items must be constant expressions. And in case when the left value is a string, it is not allowed to construct an array from a single string value. Either a string should be to the right of IN / !IN ( the case 2). Operations IN / !IN are not applicable to REAL numbers (still it is not allowed to compare REAL values for equality/inequality). |
I. 3. b. Special operands and functions in expressions |
| In most cases operands are either constants or variables (local or fields) or calls o functions returning a value. But in some cases operands are special.
|
I. 4. Other simple statements |
|
|
I. 5. Conditional statement CASE |
A BREAK statement is not used to finish a branch. After any branch execution entire
|
|
Classic example - solving a square equation for real numbers: |
|
||
|
Especial version of the In such case symbols ' |
|
|
Also there is a special variant |
I. 6. FOR loop statements |
|
A loop statement
|
|
|
To create an unguided infinitive loop, a special block statement is used:
|
|
A loop variable it it is integer can (as well as any integer variable) to have an attribute |
|
In case when a
|
|
The |
I. 6. a. About assigning a value to a loop variable:
|
I. 7. PUSH statements block |
|
A
Restoring is always guaranteed:
Syntax:
|
||||
|
||||
|
A special method with modifier Such method2 should not have parameters, and it can not be called directly (as well as opening method, having the
|
||||
|
||||
I. 8. DEBUG statements block |
|
A DEBUG block is intended for a temporary code injection which is required for debug purposes. In such blocks, levels of nesting blocks are not controlled. A compiler is always warning about such blocks not removed from a code. Such blocks should be removed when debugging is finished. In DEBUG blocks it is possible to declare local variables as usual. But it is not allowed to use such variables out of DEBUG blocks (though it is allowed to use it in another DEBUG block in the same function).
|
|
If there are required additional classes to compile |
|
For the
|
I. 9. SILENT statements block |
|
The block SILENT purposed to prevent the compiler from warnings on some block of code. E.g. about DEBUG statements in code.
|
I. 10. LIMIT statements block |
|
The block SILENT purposed to prevent the compiler from warnings on some block of code. E.g. about DEBUG statements in code.
|
| There are following variants possible:
|
| Checks for possible exceeding of a restriction specified are done (usually) each 65535 loop iterations done in the AL-IV code. So, final exceed of a limit can be discovered later to the actual exceeding after that 64K iterations executed between checks. In case of a limit exceeding the code in a block stops running and running continued from a statement next to the block. And if some PUSH statements were executing in between, all these are finished correctly with a correspondent POP operation (e.g. restoring a variable value). |
I. 11. LIKE statement |
|
(Do not mean the comparison operation LIKE between two strings in an expression!)
The
|
||||
|
An example: |
||||
|
||||
|
Additionally, while calling the
Lists of replacements are enclosed into parentheses and listed via comma. A replacement should have a multiplier
following its right bracket in form All the replacements are done just before compiling the LIKE statement having such replacements defined. Both pattern and replacement strings can be enclosed into apostrophes. Only the string right to the symbol ==> can be empty, but patterns always should not be empty strings. |
|
And please remember:
So do not overuse the |
I. 12. REVERT statement |
|
The
|
|
An example: |
|
II. Variables, constants and data types |
II. 1. Simple data types |
II. 1. a. Names of data types, data types classification |
|
There are predefined simple data types which can not be redefined:
|
|
|
|
|
For data types a precision is never specified:
|
|
Also there is the special enumeration type It is allowed to use the keyword |
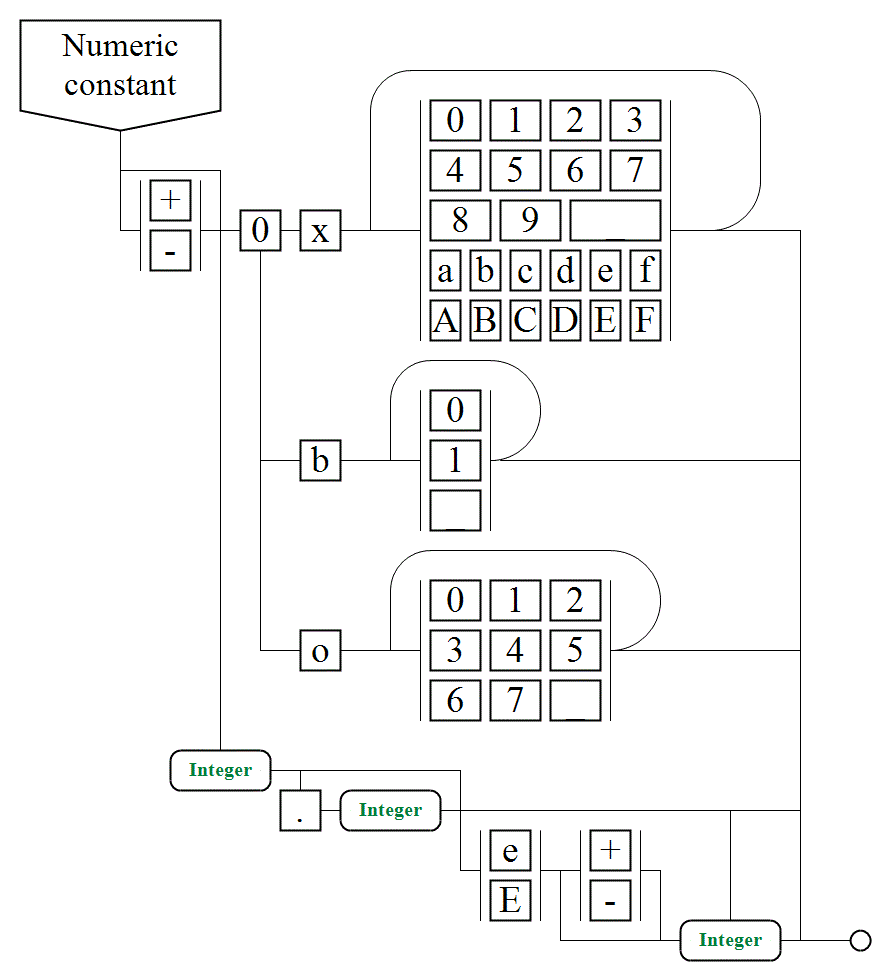
II. 1. a. Writing constants of base data types |
|
|
|
|
|
|
|
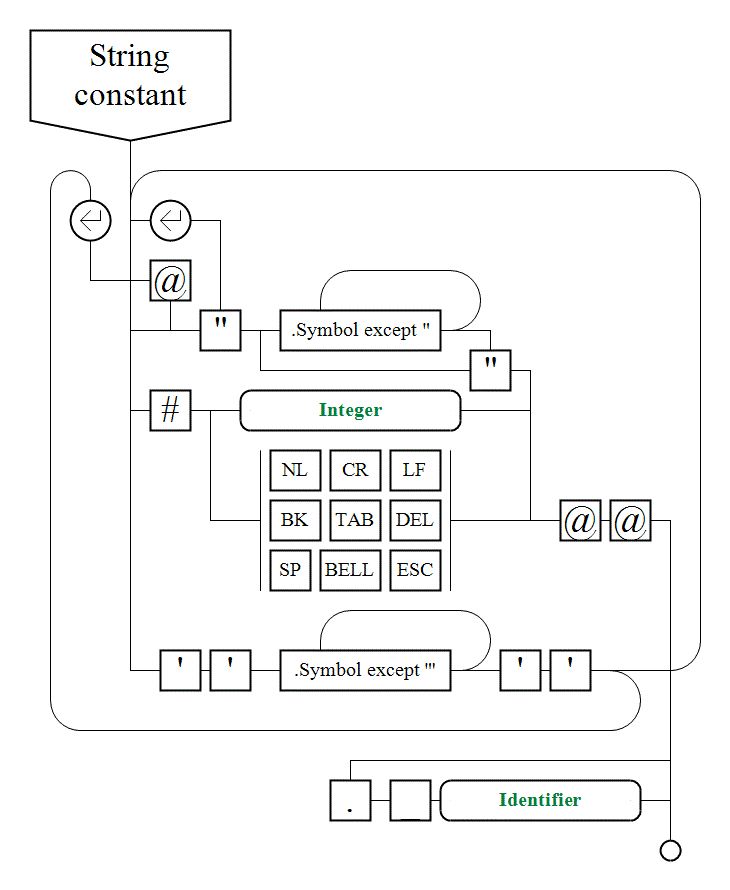
II. 1. c. Strings |
|
String data type STR is intended to handle strings of characters and single characters. The AL-IV has no a special data type to represent single characters which is represented in a STR value with the length 1.
To access separate characters of a string (both for read and write) the indexing operation is used: S.[i] where:
Certainly this is a safe operation (like any others in the AL-IV): if you read out of a range, an empty string "" with the length 0 is returned. If write out of range, nothnig is changed.
The dot symbol between the string and its index in square brackets allows to distinct the string indexing operation from an array indexing. This is especially useful in cases when working with symbols and substrings is mixed with working with arrays of strings.
There is also an operation of substring extraction: S.[i TO j]. The extracted substring (from the character with the index i to the character with the index j inclusively) can not be used at the left side of an assignment. But it operates in all other situations like a usual string operand.
Like for an array, symbol '*' in square brackets can be used as an especial value equal to the index of the last character in the string. Correspondently, S[*-1] accesses the symbol previous to the last, and S[2 TO *-2] discards 2 symbols at the start and 2 symbols at the end of the string S.
Other embedded operations for strings:
Also there are following embedded/system functions:
|
II. 1. d. Enumerations |
|
A enumerated data type defines a set of named constants. The set itself is also named to make it possible to refer to it by the name.
|
ENUM {color|s_of_traffic_light} :
|
|
Operations on enumerations:
|
|
A enumeration can be used as a range for indexes of a fixed array:
In such case the enumeration items only can be used as indexes of such fixed array:
|
|
Enumeration items are not ordered and can not be compared using operations <, <=, >, >= (only
== and != are allowed). Enumeration items can form a constant array, and for pair "item - array of
items" it is possible to use operations In case of naming conflict between enumeration items from different enumerations, those should be
qualified using names of enumerations:
In case when names of enumerations are matching, a class name should also be added to a specification:
|
|
When a
|
| The special enumeration
|
II. 2. Variables and arrays |
II. 2. a. Declaration of variables |
|
A declaration of a variable is starting from a specification of its data type in {figure} brackets
(or from one of reserved data type names:
A variable always has an initial value. If there are no explicit initial value specified, a default initial value is set.
|
|
Naming variables rules: |
|
|
Case of letters in a variable name:
|
II. 2. b. Scope of view for variables, fields |
|
Constants
Class fields:
Local variables of functions and methods:
|
II. 2. c. Field modifiers |
|
If some modifiers are required for a variable, these are written in a declaration following it names and dimensions. |
|
|
Additionally to explicit modifiers above, there are also implicit variables modifiers:
|
II. 2. d. Named constants declaration |
|
Constants can be declared only on a module level, and only of embedded simple data types (
It is recommended to use uppercased names for constants. A block of constants can be named (its name is specified in {figure brackets} following the type name). Such name of a block of constants can be used while specifying restrictions on functions parameters. |
II. 2. e. Arrays declaration |
|
Array dimensions are written in square brackets following the variable names.
|
|
Initial values for items of arrays are always provided as well as for all other variables.
|
II. 2. f. Array constructor |
|
An array constructor is a sequence of items in square brackets in a form:
Only constants are allowed as values. |
|
An array constructor can be used as the second operand of an operation checking if the first operand is
present in the second array |
II. 2. g. Using arrays |
|
Main specific operations with arrays:
Passing an array as a parameter to a function:
It is not allowed:
|
|
Special indexing arrays with the symbol '*':
|
II. 3. Functions |
II. 3. a. Function header |
FUNCTION
names (parameters) ==> result_type , modifiers :
.
|
|
|
|
|
|
|
|
|
Parameters are separated with comma.
|
|
For an array parameter its dimensions are listed following its names.
|
|
Integer parameters can have attribute |
|
Parameters can not have its own modifiers. Parameters which are not used in the function body, should have a substring "dummy" in its name (in any registry case). Scalar parameters are always passed by the value (formally) and can not be changed in the function body. |
|
Parameters can have restrictions on values passed or be used in restrictions to other parameters.
Parameters can be restricted with lists of constant values of ranges independently, or dependently from
values of other parameters passed.. See function modifiers |
|
For operators, input data types are its parameters. At least one of input data types should be a class or a structure. In the operator body (which is always a single expression) to refer to that type parameters, letters A and B are used (though there are no such letters on the operator header). The "A" letter is used to refer to the first parameter, "B" - to the second. In case of redefining the unary operator "-", the "A" letter is used to refer to the single input data type. |
|
In case of common functions in place of a parameter type a list of possible types enclosed into
parenthesis can be found like |
|
|
If a result type is not specified (together with the symbol '==>'), then the function is not returning a result.
|
|
A sample of a function counting number of dots in a string:
|
|
In case of a common function result type can be represented as a list of types enclosed into figure
brackets: |
|
|
It is possible to write following the result type returning:
|
|
|
| Function modifiers are listed via comma. Following modifiers are possible:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
In case when some redefined operators are used in the function body, it should have the modifier |
II. 3. b. Function body |
|
Function body consist of statements located and it is finished by a dot symbol.
|
|
If the requirements above are not satisfied. then it is necessary to mark entire class with the modifier
|
|
In case of a single assignment statement, in which an expression is assigned to the pseudo variable
|
II. 3. c. Calling functions |
|
Parenthesis are necessary to be used only if actual parameters are present.
|
III. Classes and objects |
III. 1. Classes |
III. 1. a. Class declaration |
|
Syntax.
One file contains exactly one class definition. All other declarations (enumerations, functions, constants, fields) are located only in classes and belong them. The are no global (static) class fields, all the fields are members of certain objects. |
|
|
|
III. 1. b. Class modifiers |
|
A modifier for a class is written following the class names. Such as:
|
III. 1. c. Import section |
|
The first in a class (following the class header) should be specified a statements
IMPORT statements can have modifiers:
|
| Instead a reference to
a class in form {Class-name}, it is possible to specify in the import
list a reference ton .import file in form {{File-name}} where file-name
has no a path or an extension. The file specified is searching in all
the directories specified by /src project options. Such file should
contain a list of class names in form {Class-name} separated by spaces
or line feeds. There are files Standard.import, Visual.import and
Files.import prepared to be used with your projects which contain
references top the most appropriate classes in correspondent categories
in form like (e.g.): |
III. 1. d. Inheritance |
|
To specify an ancestor for a class its declaration is written in a form (immediately after
|
||||
|
When a method is redefined in a class:
A redefined method can call a base method (the same named method of the base class).
|
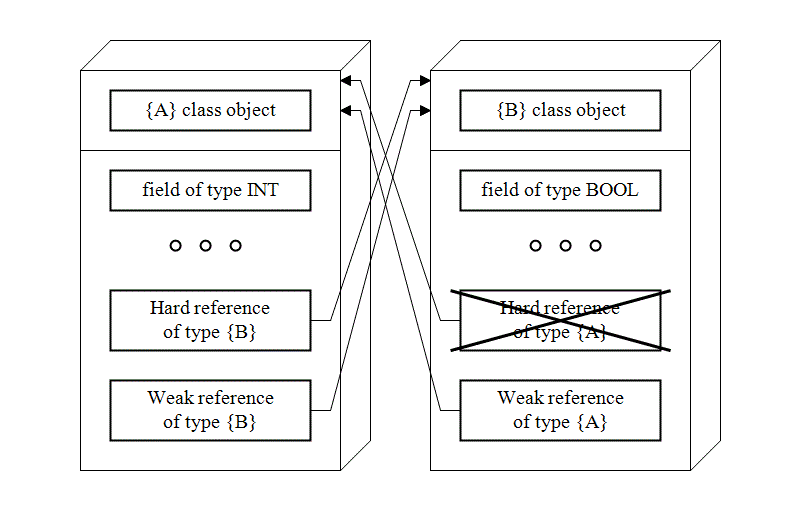
III. 1. e. Objects. Strong and weak references |
|
A variable of a class type (a class instance) is an object of the class.
|
THE RULE
|
|
III. 1. f. Fields |
|
Fields of a class are declared very like to local variables but on the same level as class methods, functions and other class declarations.
Field declaration (schematically):
|
|
|
Class fields can have modifiers listed comma separated following its declarations (but before an initialization if it is present). |
|
III. 1. g. Methods |
|
To declare a method rather then a static FUNCTION, the keyword
|
III. 2. Working with objects of classes |
III. 2. a. Creating an object instance |
|
Object construction:
|
III. 3. Other class level operators |
|
If the class has an ancestor in its hierarchy, this should be specified with the statement |
|
A class is always ended with a standalone statement |
|
Before the
|
III. 4. Ending class. History of changes. DATA[] array. |
|
A class is ended with the directive |
|
If the The block consists of messages in form:
The last message of a block should end with the dot, or it should consist from the dot only. |
|
The history of changes can be ended together with the end of the class text. But in case when the
text after the END directive contain also another information additionally to the history, it should be
ended with the special directive
E.g.:
|
IV. Structures (STRUCTURE) |
IV. 1. Declaration of a structure |
|
Syntax.
Structures are declared in a class body. Name of a structure is always start from a small letter. The name can be separated with the symbol '|': the first part is a short name of the structure. Full name of a structure can not be shorter then 8 characters. All the structures declared in a class are always accessible for all the classes importing that class.
A structure contains of:
A structure declaration is ended with the dot symbol ' |
'
|
|
A structure like a class can contain fields of ant type. But there are restrictions on fields which are
objects of classes:
If a class field is a structure, it must not be a weak reference since any variable of a structure type is a single reference onto its structure. |
|
|
All the structure variables and fields are automatically initialized with a structure (of the corresponding
type), which consists of zero fields (for numbers these are zeroes, for strings theses are empty, for objects -
|
IV. 2. Working with structures |
|
Structure is a class without methods, objects of which are always referenced by a single reference. So when
an instance of a structure is created, it is not possible to use the |
|
If one structure variable is assigned to another structure variable, then the right side of the assignment
should be ended with a call to the embedded function
E.g.: |
STRUCTURE
|
|
A similar constructor can be used to pass an actual parameter to a function in place of a structure parameter. When a structure is assigning (to another STRUCTURE variable or field), its content just is copied. |
|
When passing a structure as a function parameter, it can be used in the called function only for read, and it is not allowed to change its fields. This differs from rules of using objects of classes, for which it is possible to change its fields in a called function. Correspondently, when assign entire structure to another structure variable, its possible (and necessary) to call only Clone pseudo-method and not Dismiss. |
|
A structure can be used as a result of a function. When working with the
Structures can not be passed as parameters or returned as results of native (low-level) functions. |
|
A structure can be created with an operator creating a new object of certain class:
|
|
If the |
|
It is possible to assign structure variables of different types but having so named fields (which are of
compatible types):
In the left Methods |
|
Structure variables can be used with SQL statements ( |
IV. 3. About structures implementation in the final code |
|
No assumptions should be made how fields of structures are located in the operative memory at runtime or about its ordering and aligning onto machine words bounds. The same is about its sizes in memory and / or mechanisms of allocating memory for them. Also, any asumptions about their effectiveness (in comparison with classes or sets of variables declared separately) can be totally incorrect. Structures can be actually implemented as objects, or a subset of simple structures (which do not contain dynamic arrays, strings and object references), which can be implemented as actual structures in a target language. All what really necessary to know about structures are the fact that structures actually like simple variables are copied while assigned, and it is not possible to refer to them (using any pointers). Though, while passing them as function parameters, actually references are passed (but these are read only like simple data types parameters, and its fields can not be changed in a function). The obligatory requirement to use pseudo-functions CLONE / DISMISS is introduced to provide for a programmer that (s)he always take into account that in that case data are copied rather then referenced (and changes in a destination variable will not affect a source variable). This should decrease amount of errors caused by a misunderstanding that fact. |
V. Testing |
V. 1. General rules |
|
Class can contain special functions starting with a keyword
|
|
Which code should be tested:
A set of tests is concerned to be "covering" only if all the lines which should be tested were
executed during a class testing at least once. If this condition was not satisfied, the class should be
marked as |
|
All the sections of code in a |
|
What is not necessary to test:
|
|
Therefore while testing a class inherited from an abstract class all the not redefined methods of an abstract ancestor should be tested to ensure that a derived class is tested. It is allowed to place in an abstract class some testing functions with parameters, intended to test partially (or totally) functions of an abstract class. Tests with parameters are not called automatically but these can be called from other TEST functions. In part if to create such parameterized tests in an abstract class these can be used to simplify testing the abstract class together with derivatives of it. |
|
Testing is executing every time when a project is compiling (except cases when results of the previous testing are saved and the code did not changed from which the testing code depends, or tests was completely disabled with the key /$NOTESTS - but this depends on the compiler). During a cross-platform compiling to some target platforms (Java/Android) the testing can not be performed on the compiling stage, but using the special compilation option it is possible to build a special (pseudo-console) version of the application purposed to run tests only. But integrating results of testing into the process of compiling is not possible in such case, and results of testign should be controlled manually. In case of cross-compiling to the Linux (from the Windows) testing is possible on the source platform. But it is necessary to take into account, that the reliability of results is not 100% (still platforms are different, the same code can give different results on these two platforms). Therefore cross-platform compiling for Linux is done once for the compiler itself, and later other projects are building on the Linux using this compiler. |
V. 2. Syntax |
|
Testing function starts from a header which differs from a function header by a keyword |
|
Testing functions can have parameters but such parameterized tests are not called automatically: these can only be called from other tests. |
|
If some additional classes are required for testing functions, it is necessary to list them in |
|
Like other functions testing function also is separated onto sections with block comments
But for testing functions an additional requirement is there: each section should contain at least one |
|
An |
|
The |
VI. Embedded SQL support |
VI. 1. SQL queries encoding |
|
If a class has a method
It is actually just calls the Write method. In case of class |
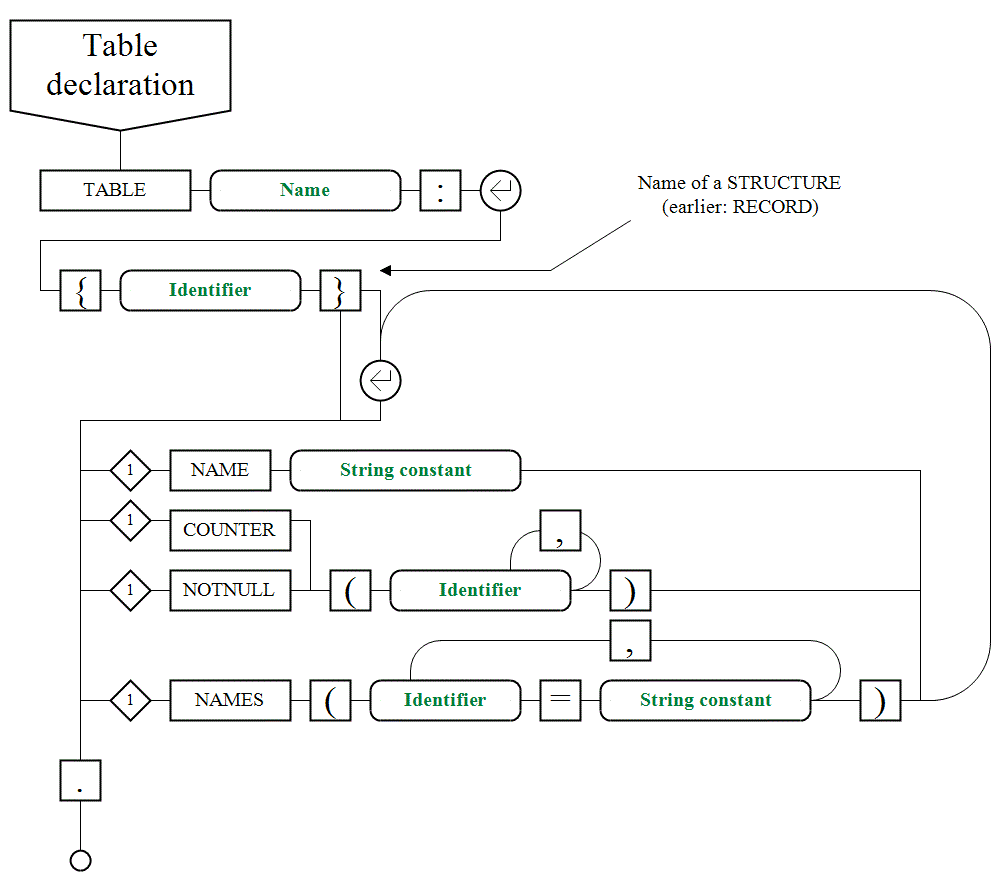
VI. 2. Database tables structure. TABLE operator |
|
When a text of SQL is set and string expression is started from one of keywords |
|
|
Such SQL queries a referencing "tables" declared by |
|
STRUCTURE {abiturient}:
|
|
VI. 3. SQL-like syntax |
|
Queries are similar to SQL but syntax is different a bit:
|
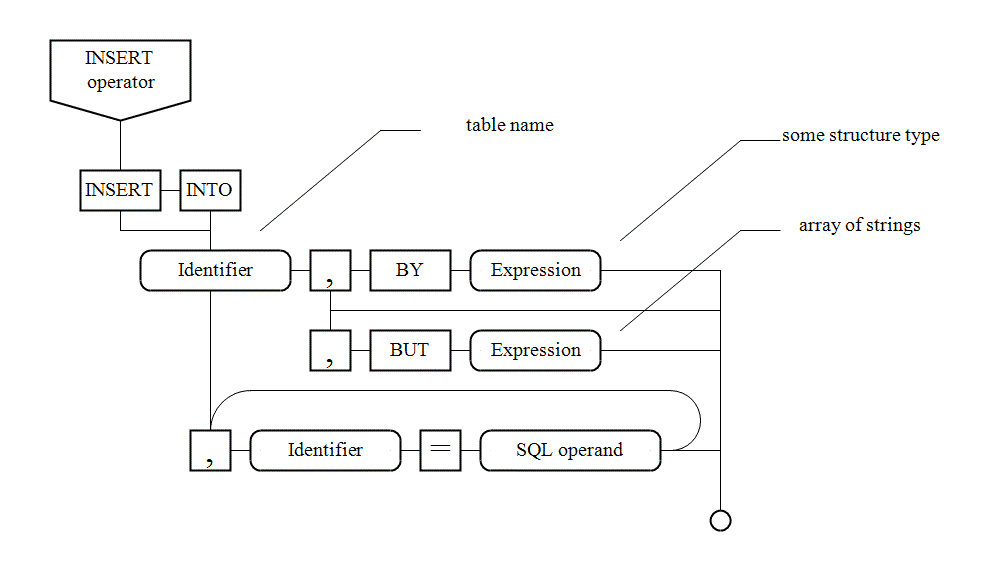
VI. 4. Executing queries INSERT, UPDATE, DELETE |
|
Queries
To obtain an identity value of just inserted record use the method
Similar, to get amount of records inserted or updated, it is necessary to call a method
When inserting records using the INSERT statement or changing records using the
In such case it is possible to skip some fields which names are listed in a string array:
If a base is configured to set values to NULLs by default, all skipped fields become NULLs. |
VI. 5. Getting results of SELECT statements |
|
To obtain results of a SELECT query:
When getting results selected:
|
VI. 6. Transactions |
|
Transactions are implemented via the PUSH-method Transaction. It can be called only in the
header of a If code was successfully executed until the ';' finishing the PUSH block, then
(dependently on the fact if a To prevent from the programmer to "forget" writing Commit, the method Transaction
has the modifier |
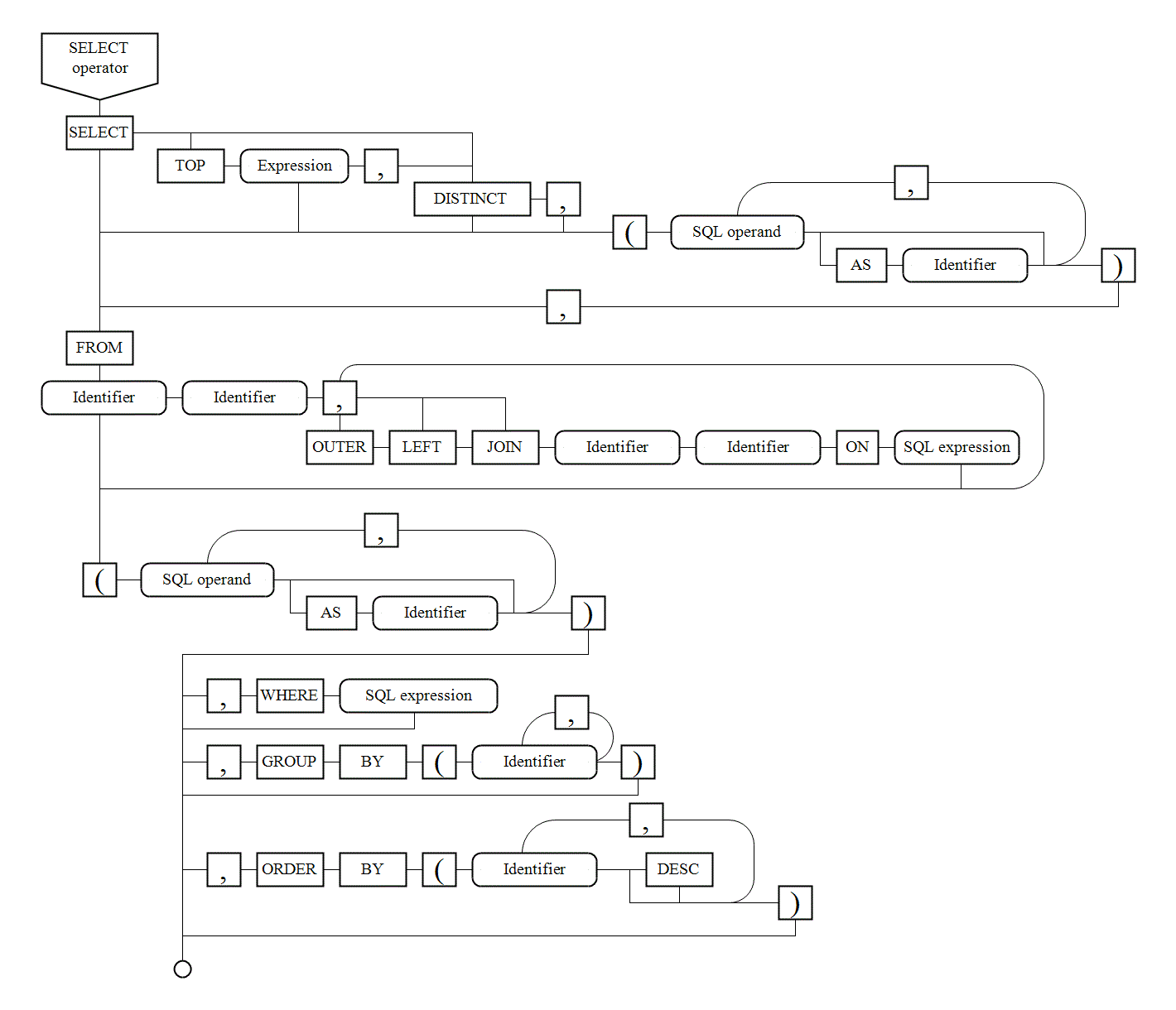
VI. 7. Syntax diagrams |
|
There are syntax diagrams below for statements generating SQL queries: |
|
|
|
|
|
|
|
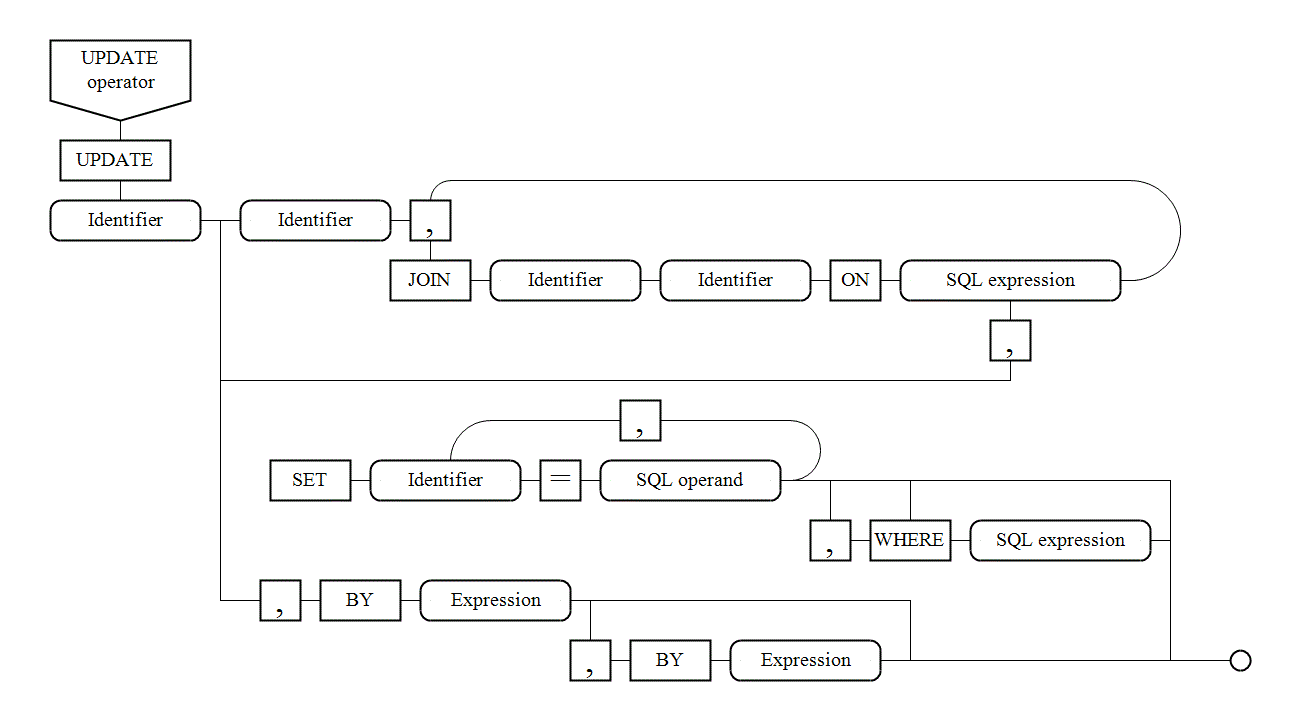
|
|
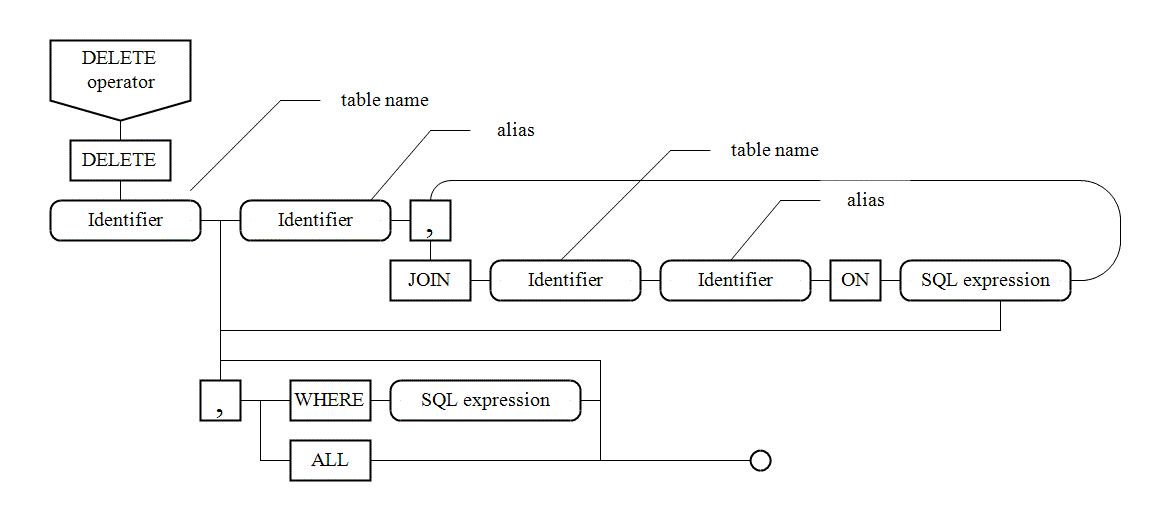
|
|
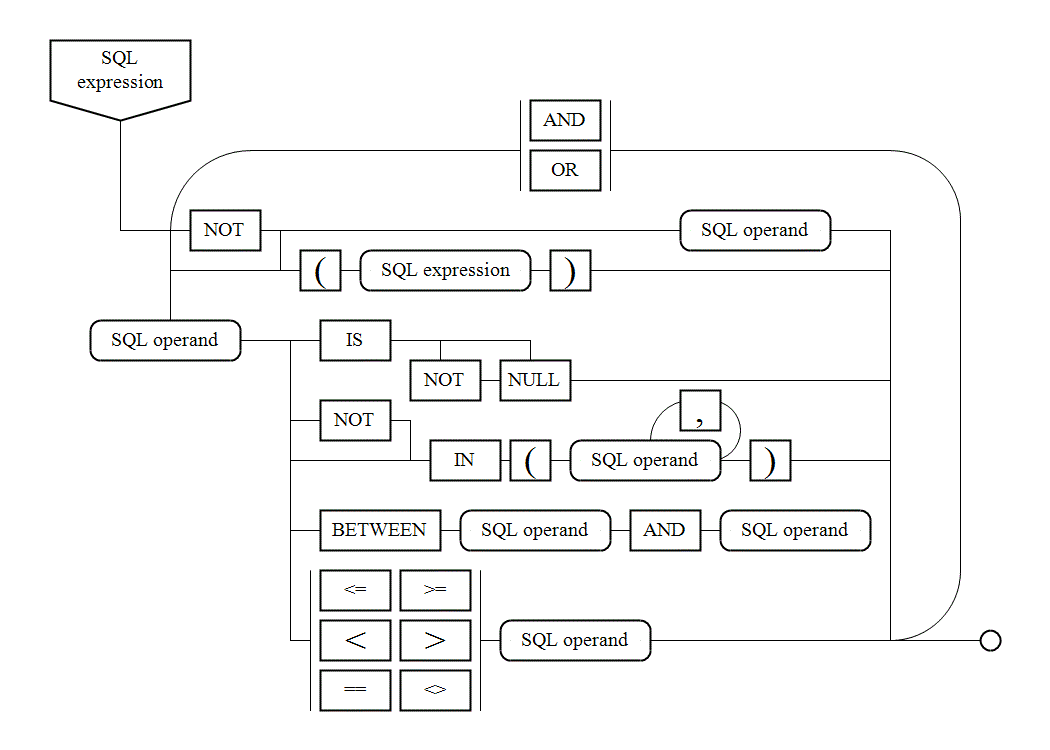
|
|
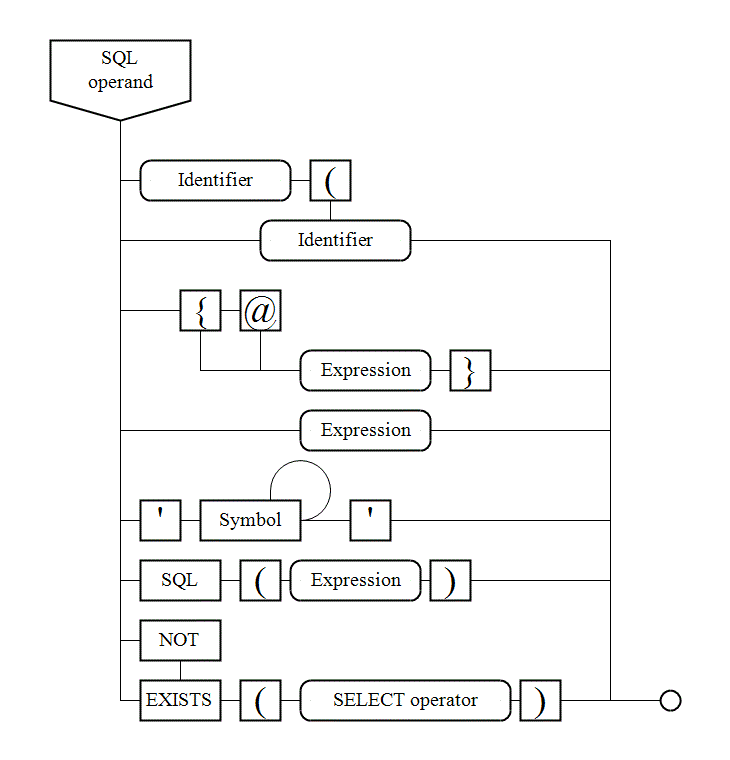
|
VII. Additionally |
VI. 1. Native (low-level) functions |
|
Native functions can be only static (not methods). These should have the modifier NATIVE. It is not allowed to use structures as its parameters or data type of the RESULT value. Therefore, objects of classes are allowed.
There are two main variants of native functions: containing only native code, and having both normal AL-IV code, and ended with native code (allowing to prepare some parameters in local variables, or check some conditions and to prevent running native code if necessary).
In the first case either string constant or named string constant is following the colon ending the
function header. If a string constant is written, it can be multi-line, with the prefix symbol
'@' (adding the new line symbol #NL after each line continued).
If a named constant is used, then the keyword |
|
In the second case, first the AL-IV code is written:
In both implementations of the function Writeln_number above, the first the parameter is checked for negative value. And both examples do the same result. |
|
The content of a string constant specified as the native function body, is inserted into resulting code almost without changes. And this should be the code on a target programming language. But some peculiarities can be there depending on a target language. E.g. for the Pascal, the first lines starting from the keyword ' var' are treating as declarations of local variables and these are inserted before the keyword ' begin' which is starting final code of a translated native function. (Actually, if the first line is starting from the ' var', then all the first lines until the last one starting from 'var' are inserted in the declaration section. Including all intermediate lines even not starting from ' var'. This allows use e.g. conditional defines in the declaration section). In all cases, for native functions returning a result, the local variable |
|
To access it own parameters and local variables, native function in its body (in the string constant) should add the prefix 'X_' to its names. To work with objects and its fields and methods it is necessary to know exactly how to access them in a native code. Usually, fields get prefixes 'F_', methods and functions - 'M_'. Take into attention, that some programming languages do not matter about letters registry case (so, names 'a' and 'A' are equal in the Pascal). It is possible to find a lot of examples of native code for C#, Pascal and Java in the functions library. |
|
Classes containing native functions should be marked with the modifier |
VII. 2. Localization of string resources |
|
The AL-IV programming language supports localization of strings via pseudo-functions in form of This construction looks like a function call but it is not a call to a function. But it tells to a compiler that a sting "Red square" should be placed into an array of localized strings, remember its index in the array and use it to extract the string from the localization array. Actually, another string can be extracted, if it was replacing the original one in result of working of localization operations. All the names of such string resources (pseudo-functions) should be unique in a class. A special class |
|
When using the class The method Localize has an additional parameter Prefix which allows translating not all the strings, but only those having names starting from a certain prefix (the Prefix is provided without leading underscore character). An empty string means translating all the strings independently of resource names. |
|
When the Localize method is called it is first is calling a method |
|
By default a directory where an application is located is used as a place to store language files. Or if
it is impossible to write there a special application data directory is used. Or it is possible to set such
directory explicitly (calling |
|
It is important that if new strings to translate were added while developing an application, then these
are spread not only to an original language file stored by |
VII. 3. STORE - hidden parameters |
|
A modifier STORE for a method creates hidden (for a caller side) integer parameter which value is stored on a caller side. A name of a parameter is specified in parenthesis, and also its initial value can be specified additionally:
|
|
|
For each method call in a calling class a hidden integer field is created for the stored parameter, and this field is passed to the method by a reference implicitly. Passing by a reference means that if the method changes a STORE-parameter, then after it is finished, new value become the value of the hidden field. And on the next call of the same method in the same line of code, this new value will be passed as an additional parameter. |
|
|
To reset stored hidden parameter values it is possible to call a method having a modifier |
|
|
Modifiers An example of accessing listview by column names: |
|
|
|
|
In the above example, the |
|
VII. 4. Abandoned and deprecated classes, structures, enumerations, fields, functions |
|
While your classes and libraries are developing, you can find it necessary to re-write some things. Some functions, fields and so on becomes too old, supporting it costs more and more, some things are replaced with others etc. To make it possible to control on a language level of a process of a distinction of old entities and provide smooth transition to new features, following modifiers are added to the AL-IV:
|
|
There is another possible usage of modifiers For example the class Unfortunately the message from the compiler will not be firing in case when an instance of the class |
VII. 5. Restrictions to parameter values |
|
A function can have modifiers
|
|
Unconditional restriction has a form
or (for REAL data type):
or (without specifying certain value):
|
|
A conditional restriction has a form:
or
|
|
When this can be useful?
E.g., to implement wrappers to the OpenGL library. It is possible to simplify the work just creating simple wrappers to correspondent OpenGL functions and pass just integer constants, but to add restrictions for such parameters to provide checking for only allowed sets of constants. This is much more simple then to create a set of classes or to use enumerated values (since the same values can be used in different functions for different purposes). Restrictions are providing working of classic OpenGL code (e.g. samples from NeHe etc.), almost without any changes (it is sufficient to remove symbols ';' at ends of lines). |
VII. 6. Infinitive loop control |
|
VII. 7. Code optimizations. INLINE insertions |
|
VII. 8. Code optimizations. UNROLL for FOR loops |
|
VII. 9. Syntax sugar |
|
a. If there are several sequential assignments in code (or append to a string or to an array) with the
same destination variable, then in following statements can be replaced with the.. symbol (two dots). Note
that in case when the destination is an array (in an append statement array[] << item), then it is not
allowed to omit brackets. For example:
|
|
b. If the target was an object, following assignments to its fields can be replaced with three dots
(first two replacing the object, the 3rd - is the normal dot):
|
|
c. It is allowed in case of an assignment to a filed specified after a chain of dereferencing operations
(separated with dots, e.g. A.B.C(params).D[index].E), to specify also which field will be a target for
following continued assignment/ append statements. For this, instead of a dot in a correspondent position
(after the default target field replaced later with double dots), three dots symbol is used. E.g.:
|
|
d. If in a single expression there are several sub-expressions of form A.B[index].C(params).D, and then
entire chain is replicated (except the last field) then the second and following sub-expressions can be
written in very short form: .E, .F etc. Note that leading operation signs like '-', '!',
'~' are not parts of such expressions and should be written. E.g.:
e. In
f. In console output statements (
g. A function, which result is defined by a single expression can be written in a very short form:
(And the space is not required between ':' and '=', symbol ':=' is allowed too).
|
VII. 10. Short help on "embedded" functions |
|
The reason why such "embedded" functions exist is that it is not possible staying in the language rules frames to define strictly their parameters/ results. E.g. the syntax & semantics do not allow to specify a parameter as "an array of any type". At the same time it is convenient to have a set of same named common functions to manipulate with arrays independent of its items types.
Note: with introducing functions "overloading" the main such reason can be partially eliminated. But therefore there is a problem to refer to "any structure" or "any enumeration" type: the AL-IV is not ready to supply such templates.
Since all the functions in the below table are static, these can be called either in the classic form foo(x, y, z) or in the prefix form x.foo(y, z).
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
All the embedded functions can be identified by capitalized names, e.g.: A[].COUNT |
VII. 11. Generic functions |
|
Generic (or overloaded) functions have parameters with variant types of parameters (and sometimes of the RESULT).
A type of a parameter (and may be, of a result) can be represented with a list of types enclosed into parenthesis. E.g.:
|
FUNCTION Min|imum_of_two_values(
|
|
Rules:
1. Only static functions can have variant type of parameters/result, at least, one parameter should be of such type.
2. It is not allowed to define only result to be of the variant type: at least one parameter also should be of such type, too.
3. All the parameters (and if the result is of variant type, then it is too) should have the same amount of variants in lists of types. The order of variants also is important, and all the types with the same index creates a version of the function with certain set of types of parameters/result.
4. The first parameter having variant types list should have all the types in the list different. To decide which version of the generic function is called the first parameter type is analyzed. |
|
In the body of a generic function special variant of the |
FUNCTION S|tr|ing_from_rect_or_point(
|
|
The list of variants determining a branch of such conditional statement contains of items N/type where N is an index of the type in the list of types of the parameter (starting from 1), and type - is the corresponding type of the first variant type parameter.
Like in case of enumerations as conditions, the |
|
In differ from usual code, while compiling each variant of such "generic" function, all its branches not corresponding to a currently selected signature are just ignored. So, all local variables declared in such branches become "invisible" for other code.
When such overloaded function is called the compiler searches it between available functions by name(s) and signatures of variable type parameters. |
VII. 12. Indexing methods .[] - multi-dimensional arrays |
|
It is possible to declare a single method which name is replaced with the dot '.' and
parameters are listed in square brackets: so called.[]-method. To call such method for an object X,
following like-array-access notation used:
Additionally if for such method a setter method is declared, then such method can be used at the left
side of an assignment statement:
|
|
Such methods are used e.g. to implement multi-dimensional arrays like in class |
--------------------------------
'access Items[] via .[i, j] method'
|
VII. 13. Operators |
|
In the article devoted to functions declaration syntax, operators was already specified (shortly). Now more detailed. |
|
Operator is a static function purposed to be called in place of four arithmetic operations: +, -, *,
/. Its declaration differs from the declaration of a usual function:
E.g.:
Additionally to operators with two operands, also the operator can be defined for the operation
'-' with a single parameter:
|
|
At least one of types of input parameters should differ from basis types: |
|
To use operators in a function, it should have the modifier
|
|
Parameter names in the declaration are omitted but names |
|
A class containing OPERATORs defined, should have the modifier |
|
An example of the operator code: |
OPERATOR {Matrix} * REAL ==> {Matrix}, NEW
|
VII. 14. Multi-threading |
|
Multi-threading in the AL-IV is implemented by the class Threads form a hierarchy: if A runs B, then A becomes the master of B, and B depends on A. If the A is finished, B still can continue working but it can not more pass handled objects back: these just auto-destroy in such cases. The thread object when it is started also disappear actually from the memory of the master thread as
an object. But on the side of A, a phantom mirror object is created for it, and references from the
original B object are redirected to that phantom object which can be used as a controller. The master
thread can get from the controller some information about the status of the thread started ( To implement some process executing in a separate thread, it is necessary to inherit your own class
from |
|
Sometimes it is desired to get additional info on a progress of executing a task running in a thread
running. E.g. to indicate a progress of executing the task in percents. In addition to a regular method
of creating objects on the task side and sending them to a master thread ( |
VIII. Why one more programming language is necessary? |
VIII. 1. Real multi-platform support |
|
Yes, it is always possible to create applications which really are multi-platform. To do this, it is necessary to select a language (C++, C#, Java, Pascal) and to use some framework (or classes library). On that way a lot of adventures and disappointments. Adventures - because authors or these languages and frameworks very often have its own mind about what is important and what is not necessary for you. They go ways which were not known for you before. Be ready that to solve a tiny problem you will spend weeks digging entire Internet, reading dozens of forum pages etc. Disappointments - because sometimes you will have to redesign entire project removing desired features due to restrictions of a selected tool. Or even stop using the tool and to search another more comfortable (may be more expensive), and then to re-write all earlier written code. |
|
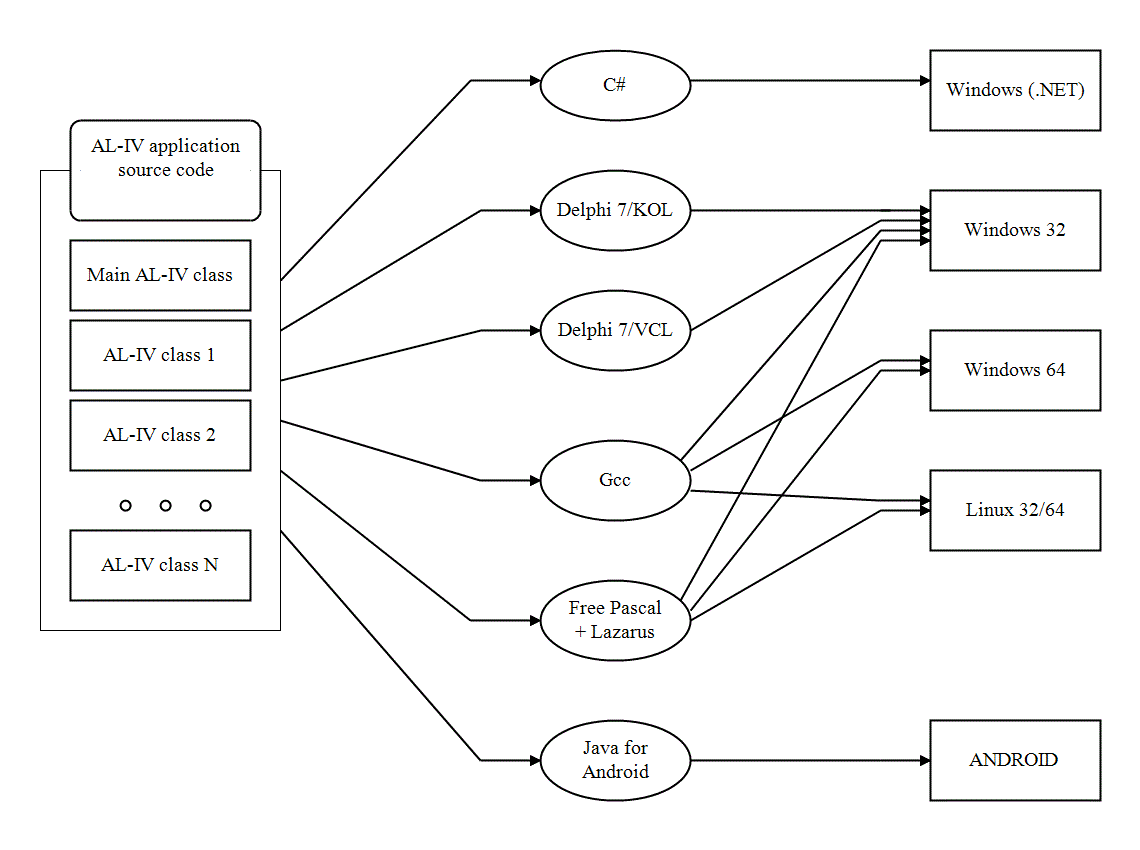
And what fundamental distinction of the AL-IV in case of multi-platform support, if it is just an extension over one of existing programming languages (under C#, or Delphi, or Free Pascal, or Java) ? The peculiarity of the Al-IV is that it is initially is not oriented on a certain platform. You write your Al-IV code only once. And to launch the application on another platform it is sufficiently to correct configuration files of a project and to call the compiler. It is just necessary to provide a support of a desired platform. Fortunately, there are not too many platforms. There is a probability that in a finite time we will have support of all the desired platforms. For this moment (June, 2019) the platforms supported are: |
|
|
|
What if one if branches supported disappear suddenly (e.g. a desired target platform become not supporting or a developer tool become more expensive to pay for it) ? There is an answer on that question. It is in the simplicity of the AL-IV. The compiler for it (which is compiling to a some intermediate language) can be prepared for a short enough time. It is always possible to return to a code generation for C++/Java/Python/... or to make another generator. A task of creating wrapper native classes implementing base libraries functionality for a certain platform can be harder. But this also can be solved since base library also is simple enough and projected to simplify such task as much as possible. |
VIII. 2. Safety |
|
Actually all the modern programming languages were developed from ancient primitive assembling languages, allowing not safe operations, address arithmetic, not controlling array bounds etc. There are no existing high level programming languages in which it could not be possible to get an exception in result of an erroneous access to a zero address or in some hard cases to corrupt an arbitrary memory block. You can use so called "managed" memory (in C++ this i an option, in C# the most of objects are in such memory), or to use none-objects (in the Objective-C). But part of code always will be written in a not safe old style, and you could not fix this (even in case if that code is yours). Even in modern C# and Java you are not free from necessity to provide checking if an object passed to a function is equal to null, or to provide exceptions handling in your code. |
|
In case of t AL-IV, the situation is different totally. On the compiler level (and the Alfour language itself) an index value is checking for a bounds when an array is accessing (providing dummy item or ignoring write to the array operation if bounds are exceeding), accessing unassigned objects, it is guaranteed initialization of all the variables, it is preventing infinitive looping and recursion. There are there embedded testing capabilities (with a control of a covering of code with tests). Programming with AL-IV really become relaxing and regular work, without extreme and adventures. |
|
Exclusions are not possible in the AL-IV. When developing native methods/ functions it is recommended to follow this paradigm providing in the final code in case of an exception handling it to provide working with it in a style of post-handling (when errors just are collected in a system array and can be accessed later by a final code, just to get know if there were errors while a function was called. In many cases it is sufficient to make a message about errors or just log it, and it is not necessary to crash). |
VIII. 3. Why new syntax? |
|
Really, it is always possible to stay in frames of some of existing syntax rule set, but to change semantics. |
|
While developing new syntax the main purpose was to simplify working with source code using an arbitrary text editor (supporting UTF-8, this was an only requirement for such text editor). |
|
It is actually from here a requirement to write keywords only in the UPPER CASE. In such case source code is much easier to read (and too hard to edit). |
|
What about an absence of a starting bracket of a block statement, and a special symbol ending each simple statement. The absence of these makes text more clear, and simplifies editing it (for operations like re-factoring). And this does not make reading harder. |
|
What about restrictions on amount of nesting blocks, on amount of statements between block comments. These restrictions do not effect a programmer freedom a lot. When we have too many nesting levels, this make code harder to read and understand. When using several indentation levels, accessible line width becomes too small to fit sufficiently long statements, and we have more often to split lines of code. So, the requirement to move deeply nesting blocks of code to outer methods/functions is very correct and useful. It is not hard at all to split too long sequences of statements Separating these with block comments i not too hard requirement at all. |
|
The only question left is about a restriction on three only parameters for AL-IV methods/functions. Initially, when such requirement was introducing it was supposed that if the rule become too hard to follow it, this can be changed or removed at all. But while developing sufficiently complex applications (such as the al-IV compiler, its IDE text editor and some other) this was found that the requirement is not impossible to satisfy, and very useful to make developing easier. For functions/ methods having not more then 3 parameters it is mach simpler to remember its parameters rather then to use special IDE to pop-up help on method parameters each time it is used. The restriction finally was removed and replaced with a requirement to specify parameter names in form of assignment (at least from the fourth). But this was done just to simplify code re-factoring (by moving pieces of code from internal blocks out to separate functions) and adaptation of code earlier written on other programming languages. |
VIII. 4. Where is "while" loop statement? |
|
Loops of form "while" / "repeat...until" are not safe, since these can lead to infinitive loops without any chance to leave such loop. Loops of form FOR i IN [...] are safe for that since these earlier or later but finished (it is possible that it could be a lot of time but not the eternity). |
|
While programming in the ALfour, in place where it could be suitable to use "while" in other
languages, use instead the FOR statement setting as a range (for example) [0 TO N] where N is a maximum
possible amount of iterations. And the first statement of such FOR statement should be a conditional BREAK
on the anti-condition of the loop continuation:
|
VIII. 5. Why new memory management rules? |
|
Since the time when a heap of dynamic data was invented, there were only one actually new useful change in memory management: automatic objects destroying on its usage counter value becoming zero. Therefore it was found immediately that in many times closed chains of references can be created (references from objects to objects increasing its usage counters), which in result prevent objects from automatic freeing still its usage counters never achieve zero value. To fix the problem the so named garbage cleaner was introduced. Unfortunately, such procedure translates all the systems built on base of this technology for releasing actually unused objects into a category of slow and unpredictable. And this means that such programming environments can not be used to create real time systems or even to use in time-critical systems of mass service. |
|
Yes it is always possible to refuce for critical subsystems from the managed memory and to develop in the old style directly controlling all the memory usage. But in such case totally disappear all the advantages of automatic memory management. And this is much more difficult still programmers usually do not do all the work from the scratch but use external libraries of classes and functions. If they can not use automatic releasing objects, then in many cases these should refuse from a lot of libraries. In result, capabilities of programming become restricting, and developing become more expensive and slow. |
|
It is contrary another situation in case when you can use automatically releasing objects but it is not necessary to refuse from real time systems developing. Still a garbage cleaning is not necessary, objects are releasing exactly at the moment when this is necessary. Is not this a dream for a programmer. |
|
Certainly in case of new way it is necessary to change a bit a strategy of objects creating. At least a programmer should think about a life time of an object at the point where it is creating. And we should reserve arrays to store references to dynamic child objects. But this is not too great loose in comparison to a possibility to refuse at all from the garbage collector (and from the garbage in the heap). |
VIII. 6. Why embedded SQL statements? |
|
Really, how a desire to make the programming language as simple as possible is combining with embedding of a direct support for SQL expressions? An answer is following: such support allows to check a lot of SQL semantics on the stage of compiling (rather then at run-time). Among them we can check: a correspondence of field names in queries to real fields (declared in TABLE definitions), a correctness of its usage (null fields, auto-increment fields, which could not be set in UPDATE statement). And certainly to check the SQL syntax, too. Such checks are done on a compiling stage reducing a possibility that a program which works with data bases, can be run with explicit errors in SQL code. |
|
Such principal - a possibility of a static analysis of a correctness of operations on a compiling stage - makes developing much simpler. Unfortunately what is concerning SQL in modern programming such principal is not applying though working with data bases is one of key technologies in a modern practice. In the AL-IV this is fixed. |
|
In differ to a generic programming the embedding some specialized features into the language (such as SQL, or complex numbers) actually do not increase a minimal necessary programming level. While writing the code, you just do not use such features, and even could be not know about these existence. While reading an alien code, you should to learn the possibility if you found it in the code. But learning some additional possibility is much easier than:
|
VIII. 7. Why there are no possibility to control which precision to use for (numeric) variables? |
|
Because this makes your code simpler (and minimizes amount of errors lead from using in calculations of data of almost the same type but with different data precision). In many of modern programming languages it is possible to define data types dual ways: for values for which the precision is not important, a base data type is used (e.g. Integer). But in cases when it is not enough or otherwise if it is necessary to economy memory, data types with special precision are used (Int64, SmallInt, ShortInt). |
|
In result, a lot of data types and its combinations are present in a code. And we have to take into account situations when a precision of one variable or result of some calculations is not enough to fit in another variable. (Actually, nobody takes into account such things, instead if a possibility is to get incorrect results, then such erroneous results will be obtained, without any reasonable explanation, what was occur and how it can be fixed). Why such thin specifications are necessary if these are just used actually to economy memory. It is much better to reject from those forever, making life simpler for a programmer since he (she) has not to decide each time which variation of a type to use now. |
|
By similar reason there are no unsigned data type in the AL-IV (like in Java, too). And it is not possible to specify bit depth for each variable separately. Only for all the integer or real numbers in a program, specifying compiler options (/int32, /$REAL=EXTENDED/DOUBLE/SINGLE). |
VIII. 8. Where is CHAR data type? |
|
This type became too old and it is not actual for modern conditions. In case of using UTF-8 encoding, one character can occupy in memory more then one byte, so to store it we have to use a string. What we finally have in AL-IV. |
|
In the AL-IV each string character is a substring. So, extracting a symbol using operation like S[n], we actually call the function S.Substring(n, 1). |
VIII. 9. Why there are no pointers to STRUCTUREs? |
|
Because records are introduced into the language only to allow data aggregation without dynamic data allocations. And these guarantee that a structure is always a single references so when the control flow leave its scope, it immediately releases the occupied memory. |
|
Records are intermediate data types between simple data types and classes. From one side these contain separate fields (and passed to functions by reference actually). From another side these are assigned like simple variables (just copying its content) and can not be modified in functions where these are passed as parameters (i.e. these are always passed as constant values, in notation of C++/Java/Pascal - const). |
|
In the AL-IV it is not possible to work with pointers to structures or its parts. |
|
An absence of pointers and addressing arithmetic essentially increases code safety. Indexing of items in arrays is much more safe operation since the compiler have an information which object (array) code is accessing, and it can provide a control on its bounds exceeding, at least at run time. |
VIII. 10. Code brittleness |
a. Short names
It is possible to use short names of variables to shorten code. As well in earlier days when programmers used very short (one- two- letters) names for variables and this was not a crime. Only the difference is what the compiler demands you to provide also a long version of the name adding symbols following the '|' sign to fulfill it to at least 8 characters. So if the reader desires to understand what the variable is purposed to (s)he can go to its declaration and read its whole name. Or, in case of a special IDE, just click on the name to get is declaration shown as a hint.
|
b. Prefix functions calls
It is possible to minimize amount of parenthesis replacing classic call of functions to the prefix form.
E.g.:
Compare to:
The first version (prefix) is shorter a bit and much more understandable. Though both variants are correct in AL-IV. |
c. Removing surplus checksIt is not necessary to check always if the object variable is null (in case of the AL-IV, is NONE). The AL-IV compiler add all necessary checks itself, and in case of the NONE value calling its methods or reading/writing fields does not lead to exceptions or other kinds of failures. In most cases while reading values the NONE value of a correspondent type is obtained (0 / "" / FALSE in case of numbers / strings / BOOL values), and nothing done in case of writing. Also it is not necessary to think about zero division, or operations with NaN operand (the NaN will be returned). If you do not like the result obtained you can make efforts to find a reason and to fix it, but there are no other faults like application crash should occur. So, in most cases it is enough to write for example:
rather then
You also do not need to take into account possible zero divisions or calculating results on base of NaN operands. In such case, just NaN will be returned. An application crash is not provided. If a value obtained is not satisfying you, try to find a reason of a failure and fix it. But this is exactly is not a reason to crash entire application at all. |
d. LIKE statementsIn many cases it is not necessary to do refactoring while code writing only just to reuse a piece of code already written several lines above. Yes, certainly, it is possible to re-design it as a separate function, to come up with a name for it, to guess how to pass parameters to it etc. and all these just to call it a couple times. In case of the AL-IV it is just possible to bound the code selected to re-write with comments:
and later to "call" it:
LIKE.......... 'do not want to write again'
This is looking and working like a macros (which certainly is very bad if this would be a C language) but
without any possibility to organize nesting |
e. Formatting block statements
There are not block begin/end or {...} brackets. This allows to economy a couple of lines of code on each nesting block of code. Code becomes compact like the Python but there are no problems there in case when code is reformatted since only ending ';' symbols are defining actual nesting level.
When going onto new line of code there are no special characters contaminating the source. It is sufficient to follow some simple rules like write '(', '[', ',' at the end of a line interrupting or to continue on new line with some operations like '+', '-' etc. |
f. Declaring local variables
Local variables are declaring at points where those are assigned first time, in most cases. And (this is important and really differs from the most of known programming languages) these are visible to the end of the function, independently of the nesting level of the block code where the variable was declared. If for some reasons code do not achieve the block where the variable was declared, anyway in all the code below the variable can be safely accessed with the NONE (or 0, or "", or FALSE etc.) value assigned to it in any case.
The only lack is in case when the variable is used to accumulate some value (counter, or collection) in a nested loop which can be run twice or more: certainly, in such case the variable should be initialized before entering the nesting loop. If you forget to do so this can brake your algorithm (but not to crash the application). |
g. Automatic releasing of objects no more used
For the most of modern languages this is not the discover. But the AL-IV does not require the garbage collector. This allows to compile code for systems/ target languages/ platforms which do not have one (e.g. Delphi32/ Free Pascal) and still to have the automatic objects releasing on zeroing reference counters on them. This also makes code shorter still it is not necessary to provide a code releasing objects manually. |
Content |
Home
|